前言
由于工作原因,笔者曾经做过一段时间的爬虫开发,所以对于一些常见的爬虫技巧也基本掌握,所以站在爬虫开发的角度来看它的对立面更具有针对性。如果对爬虫的一些开发技巧感兴趣也可以转到笔者总结的GitHub仓库。本文为技术分享(纯手打),可能有误望谅解。
常见反爬虫措施
反爬虫主要在 屏蔽抓包,登录加密,使用验证码,用户行为检测,屏蔽自动化 这几个方面做一些措施。爬虫开发主要是分析你的网站或者app的Http请求,然后使用代码模拟发送http请求获取网站服务器的响应内容,对响应内容解析拿到想要的内容。由此可见爬虫开发的大体步骤如下:
- 借助浏览器开发者工具或者抓包工具拿到http报文信息
- 分析http报文信息,请求参数是否加密,是否依赖上次请求响应内容,是否需要cookie或请求头等
- 编写代码构造抓包工具获取的http请求,解析响应内容
在这几个步骤中可以每一步都可以对爬虫进行防范,下面我从各个端(客户端,h5端,服务端)可以采取的方法一一介绍。本文介绍的是防范爬虫的一些方向,具体的实现方案还需要开发者深入调研。
客户端反爬
1.使用极验证码
在客户端一些登录注册场景,可以给用户弹出一个登陆验证码,让用户每次登陆都需要通过验证码验证;如果是数字类验证码无疑会降低用户体验;市面上比较流行的是极验验证码,通过让用户拼图的方式来完成验证。目前最新的极验验证码似乎是收费,如果不考虑成本的话还是可以用这种方式来防止批量注册的爬虫,检验目前破解也需要一定时间成本。
2.绕过http抓包
客户端的请求一般是借助抓包工具来拿到http请求信息,抓包工具原理是在客户端上配置抓包工具监听的端口,让所有的流量都经过抓包工具。下图是一款叫做mitmproxy的抓包工具的原理:
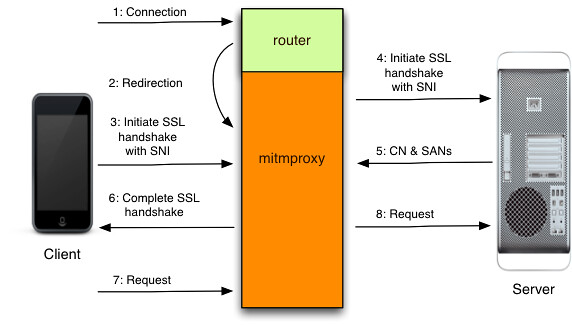
知道抓包工具的原理,便会有对应的方式不让抓包工具抓到请求包;这种方式也是笔者从目前所在公司的Android开发得知,具体实现原理如果有兴趣可自行查找资料研究。
3.检测设备是否启用代理
知道抓包工具的原理后,就知道需要对设备开启代理抓包,如果app每次发送http请求前检测一下是否使用代理则能避免被抓包。
4.代码混淆和加固
app功能开发完后一般会编译打包然后发布到应用市场,拿到这个安装包后可以使用一些工具反编译得到原源代码;如果发布的安装包未经过处理这会带来很大风险,加密参数和算法很容易被直接拿到。
5.证书锁定
为了传输安全,大多数app都会使用https协议和服务端通信,然而https协议同样可以被抓包工具抓包,在这种情况下可以使用证书锁定这种策略来屏蔽抓包。https建立连接部分流程如图:
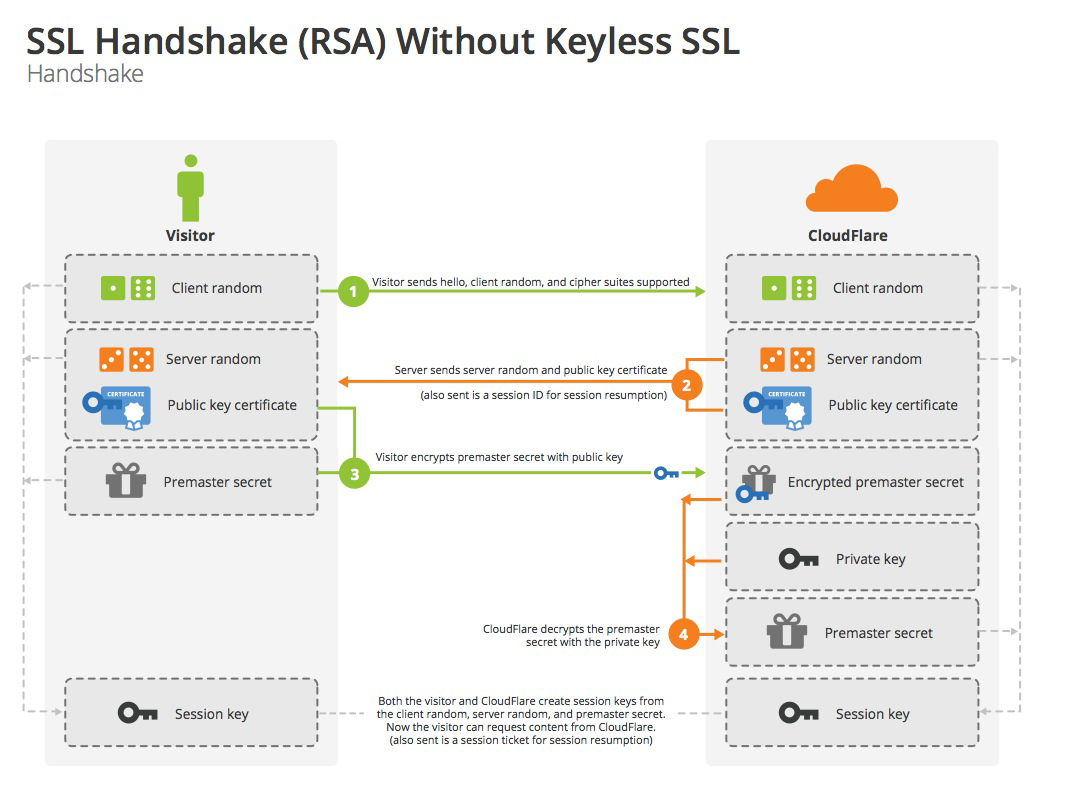
在建立连接时,服务端会下发一个安全证书给客户端,服务端拿到这个证书会校验是否信任,如果不信任则不能建立连接。在app中修改代码只信任公司配置的安全证书,每次建立连接时校验证书是否是指定的公司证书,如果是其他抓包工具证书则不能建立连接这样就很好的屏蔽了抓包。但是这种方式带来的坏处是如果线上安全证书如果有所变动将影响所有的app用户,其中的风险需要开发者评估。
6.检测Hook框架
爬虫开发中还有一种方式就是对app的函数进行Hook,Android平台常见的Hook框架 Xposed Installer 和 Cydia Substrate;具体的防范措施可以查看美团技术发布的Android Hook技术防范漫谈.IOS平台
7.检测Appium框架
在爬虫开发中如果不能拿到http请求,最后的方法一般是采用自动化来获取信息。因为自动化这种方式相对发送http请求性能急剧下降,不到最后地步一般不采用。Appium框架可用于自动化测试,也可以用来爬虫开发,一般自动化近似于一个真实用户来请求,也可以不检测。但要确保系统不是只有一种措施来防范爬虫,比如通过Appium拿到一个加密参数或者cookie等数据就可以使用http请求,这种情况下也同样需要防范,具体检测方案有兴趣客户端开发者可以自行调研。
h5端反爬
1.js/css混淆
js混淆是为了让爬虫开发者不能直接通过分析js就可以构建一个http请求,加大逆向分析难度,可将一个加密参数或一个特殊的请求头等数据放在混淆的js中生成;css混淆是为了不让爬虫开发者拿到http响应后便直接可以解析。
2.js反debug
js中使用debugger可以在打开浏览器开发者工具后一直跳到这一行代码以达到不让爬虫开发分析js的目的。破解反debug也有很多方式例如使用mitmproxy截取js的内容然后将修改debugger,但聊胜于无,能起到一点防范作用也是可以采取的。
3.cookie插件(不确定的方案)
在以往的爬虫开发经验中遇见过各式各样的反爬虫,其中有很多莫名其妙的问题。例如莫名其妙就会出现一个奇怪的cookie或其他参数,同时出现过一个奇怪的插件,于是便猜测是不是这个插件生成了cookie。这种防范措施不确定是不是有具体的方案,前端开发者如果有兴趣可自行调研。
4.检测Selenium框架
Selenium也是用于自动化的一项技术,爬虫开发无法通过逆向分析js来获得数据时一般使用自动化来完成抓取任务。一般Selenium也是可以被js检测到,通过Selenium启动的浏览器会带有一些Javascript变量,例如 Javascript变量,在非selenium环境下其值为undefined,而在selenium环境下,其值为true。js可以通过辨识这些变量来判断当前是不是Selenium环境,但当爬虫开发使用mitmproxy来篡改js,将检测Selenium环境的的js代码修改,这时检测失去作用,所以进阶的检测Selenium框架方案需要前端开发者深入调研。
5.采用ActiveX控件加密登录
对于一些和钱相关的数据,对爬虫的防范再怎么重视也不为过。一般银行系统登录都会下载一个exe安装在本地,这有效地防范了爬虫,但也为用户带来困扰;如果数据十分重要,采用这种方式还是利大于弊的,就是需要额外编写一个控件。
服务端反爬
1.业务防刷
一般app都会有一个用户模块,用户登录后才能使用,每个用户都会对应一个userId,可以根据userId来限制请求次数。
2.cookie管理
服务端可以未每个cookie的属性都赋值,不使用默认缺省值;对每个请求都设置相应的name,path等属性,这种方案需要结合系统服务端登录实现方式,如果不需要cookie登录,则不起作用。

3.ip验证
ip验证这种方式防范爬虫会降低一定的用户体验,具体实现是每隔30分钟就弹出验证码让用户校验,同时需要采用其他方案不能让爬虫破解验证码。
4.ip并发限制和检测代理ip
服务端记录每个ip单位时间内并发请求量,达到阈值直接封ip;爬虫开发一般会使用代理ip来请求,要拿到最初的ip进行记录;同时也可以检测是否使用了代理,如果是通过代理ip访问则拒绝访问。
5.检测Referer和UserAgent等请求头
在正常的用户访问中,http请求一般会带有Referer请求头,这时可以检测Refere是否正常,一般一个请求只会由特定的页面切换,如果是其它页面则说明存在爬虫嫌疑。UserAgent也可以进行检测,具体检测短时间UserAgent访问多次,同一个用户不停切换UserAgent都存在是爬虫的嫌疑。
后记
爬虫与反爬虫的博弈是一直没有尽头的,一方有新的技术另一方总有新的解决方案。本文介绍的是笔者在从事爬虫开发工作中所遇见的一些反爬措施,不一定准确但能让读者大致熟悉常见的一些反爬措施,为开发者防范爬虫起到一些启发。